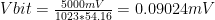A while ago one of our long time customers approached us to automate tasks on a government portal. At least here most of them are kind of ugly, work on a specific set of browser versions and are painfully slow. We already helped him with problems like this before, so instead of having someone enter manually all the data they just populate a database and then our robot does all the work, simulating the actions on the web portal.
This one is a bit different, because they introduced a captcha in order to infuriate users (seriously, it looks like they don’t want people logging in).
Most of the time they look like this:
The first thing I tried was to remove the lines and feed the result into an ocr engine. So I made a very simple filter using Pillow:
#!/usr/bin/python
from PIL import Image
import sys, os
def filter_lines(src):
w,h = src.size
stripes = []
ss = {}
for x in range(w):
count = 0
for y in range(h):
if src.getpixel( (x,y) ) != (248, 255, 255):
count += 1
if count == h:
stripes.append(x)
for x in stripes:
for y in range(h):
src.putpixel( (x,y), (248, 255, 255) )
return src
if __name__ == '__main__':
src = Image.open(sys.argv[1])
region = filter_lines(src)
region.save(sys.argv[2])
Now it looks better but after trying gocr and tesseract it still needs more work:
Just for kicks I decided to filter 100 images and overlap them, this is what I got:
That is interesting… I used this script (not the most efficient approach, but still..)
#!/usr/bin/python
from PIL import Image
import sys, os
dst = Image.new('RGB', (86, 21) )
w,h = 86, 21
for x in range(w):
for y in range(h):
dst.putpixel( (x,y), (255, 255, 255) )
for idx in range(30):
src = Image.open('filtradas/%i.bmp'%idx)
for x in range(w):
for y in range(h):
if src.getpixel( (x,y) ) != (248, 255, 255):
dst.putpixel( (x,y), (255, 0, 0) )
dst.save('overlapeada.bmp')
With this piece of information I can focus my efforts on that area only.
That font, even distorted, looks quite familiar to me. And indeed it is, it’s Helvetica.
This makes the problem a lot easier.
I grabbed a bitmapped version of the same size and made a grid that shows were can a number land assuming 8×13 symbols:
This shows that there is a slightly overlap between digits.
I went for a brute force approach, dividing the captcha in cells and comparing each one with every digit on the font with a small amount of overlap between them.
The symbols are smaller than the cell, so for every one of them I build regions on the cell and assign a score for the number of pixels that are equal on both.
The one that has a highest score is (likely) the correct number.
This is really simple, event tough we do a lot of comparisons performs ok (the images are quite small), and without tunning we got about 30% success rate (the server also adds noise and more aggressive distortions from time to time).
Have a difficult or non conventional problem? Give us a call, we are like the A-Team of technology.
This is the complete algorithm (it’s in Spanish but shouldn’t be hard to follow), can also be found here: https://gist.github.com/pardo-bsso/a6ab7aa41bad3ca32e30
#!/usr/bin/python
from PIL import Image
import sys, os
imgpatrones = []
pixelpatrones = []
for idx in range(10):
img = Image.open("patrones/%i.png" % idx).convert('RGB')
imgpatrones.append(img)
pixelpatrones.append( list(img.getdata()) )
def compara(region, patron):
pixels = list(region.getdata())
size = min(len(pixels), len(patron))
res = 0.0
for idx in range(size):
if pixels[idx] == patron[idx]:
res = res + 1
return res / size
def elimina_lineas(src):
cropeada = src.crop( (4, 1, 49, 19) )
w,h = cropeada.size
stripes = []
for x in range(w):
count = 0
for y in range(h):
if cropeada.getpixel( (x,y) ) != (248, 255, 255):
count += 1
if count == h:
stripes.append(x)
for x in stripes:
for y in range(h):
cropeada.putpixel( (x,y), (248, 255, 255) )
cropeada.putpixel( (x,y), (255, 0, 0) )
return cropeada
def crear_crops(src, celda):
limites = range(38)
xceldas = [0, 8, 16, 24, 32, 40]
xoffsets = range(-3,4)
yceldas = range(6)
boxes = []
crops = []
x = xceldas[celda]
x = [ (x+off) for off in xoffsets if (x+off) in limites ]
for left in x:
for top in yceldas:
boxes.append( (left, top, left+8, top+13) )
for box in boxes:
crops.append( src.crop(box) )
return crops
def compara_crops_con_patron(crops, patron):
scores = []
for crop in crops:
scores.append( compara(crop, pixelpatrones[patron] ))
return max(scores)
def decodifica_celda(src, celda):
pesos = []
crops = crear_crops(src, celda)
for patron in range(10):
pesos.append( compara_crops_con_patron(crops, patron) )
return pesos.index( max(pesos) )
def decodifica(filename):
original = Image.open(filename)
src = elimina_lineas(original)
res = []
for celda in range(6):
res.append( decodifica_celda(src, celda) )
return ''.join( str(x) for x in res )
if __name__ == '__main__':
print decodifica(sys.argv[1])